5/21 每日一題 (鍊結串列)
203. Remove Linked List Elements
Easy
7.2K
209
Companies
Given the head of a linked list and an integer val, remove all the nodes of the linked list that has Node.val == val, and return the new head.
Example 1:
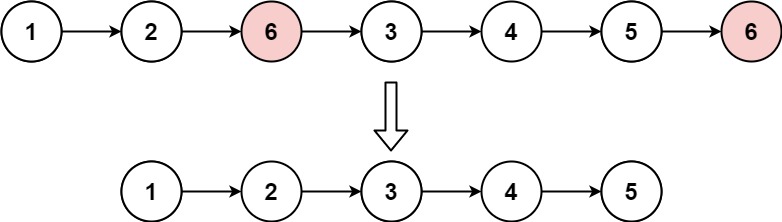
Input: head = [1,2,6,3,4,5,6], val = 6 Output: [1,2,3,4,5]
Example 2:
Input: head = [], val = 1 Output: []
Example 3:
Input: head = [7,7,7,7], val = 7 Output: []
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: Optional[ListNode], val: int) -> Optional[ListNode]:
#定義一個新節點
newlink=ListNode()
cur = newlink #保留一個最後回傳用
current = head
while current: #走訪head每一個節點
if current.val != val: #當不是val的時候,放入新鍊表
cur.next = current
cur = cur.next #新鍊表指針移動
current = current.next #持續走訪
cur.next = None
#斷開新鍊表的尾巴節點連接
#否則會繼續按照原始鍊結的模式將next為None的節點放入新鍊表中
return newlink.next
#因為一開始定義的newlink是空節點,所以回傳newlink.next
參考解答
- The linked list is empty, i.e. the head node is None.
- Multiple nodes with the target value in a row.
- The head node has the target value.
- The head node, and any number of nodes immediately after it have the target value.
- All of the nodes have the target value.
- The last node has the target value.
- 鍊錶為空,即頭節點為None。
- 連續具有目標值的多個節點。
- 頭節點具有目標值。
- 頭節點和緊隨其後的任意數量的節點都具有目標值。
- 所有節點都具有目標值。
- 最後一個節點具有目標值。
class Solution:
def removeElements(self, head, val):
"""
:type head: ListNode
:type val: int
:rtype: ListNode
"""
dummy_head = ListNode(-1)
dummy_head.next = head
current_node = dummy_head
while current_node.next != None:
if current_node.next.val == val:
current_node.next = current_node.next.next
else:
current_node = current_node.next
return dummy_head.next
張貼者:踏上開始的旅途 @ 5月 21, 2023
0 個意見
![]()

0 個意見:
張貼留言
訂閱 張貼留言 [Atom]
<< 首頁